1학년 학부 연구생 시절 진행했던 베스트 댓글 알고리즘 개편에 대한 개요이다. 임시블로그에 있던 글을 여기 기록용으로 남겨둔다.
프로그래밍에 대해 아무것도 모르던 새내기 시절 머신러닝을 해보겠다 고군분투 하던 글 들을 지금 다시 보니, 정말 민망한 흔적들이 많이 보인다…
접근
개인 연구 주제로 댓글의 긍적적, 부정적 척도를 판별하고 분석하는 프로그램을 만들어보고자 하였다.
궁극적으로 지향하는 바는 댓글의 편향성 및 신뢰성 측정을 통한 베스트 댓글 알고리즘 개편이다.
- Reorganization of the best comment algorithm by measuring the bias and reliability of comments
요약문
베댓 저널리즘이란, 베스트 댓글이 여론을 주도하는 현상을 가리키는 용어로 댓글의 영향력이 커진 것을 반영하는 신조어이다. 뉴스의 댓글 기능은 애초 기사에 관한 외부 의견을 모으고 여론을 수렴하는 장치로 출발했다. 그런데 현재는 ‘뉴스는 안 읽고 댓글만 읽는다’는 말이 나올 정도로 댓글은 여론을 조종하는 거대 장치가 되었다. 이 점을 악용하여 특정 집단이 각종 웹사이트나 SNS에서 댓글을 장악하여 여론을 조정하는 사태가 발생하고 있다. 노출빈도가 높고 영향력이 강력한 베스트 댓글 제도는, 단순추천제로 이루어지기에 쉽게 조작될 수 있다. 본 연구는 올바른 인터넷 댓글문화와 정당한 여론 조성을 위하여, 베스트 댓글 알고리즘을 개편하기 위함에 있다. 댓글의 편향성을 측정하는 알고리즘을 설계하여, 가장 편향성이 적고 신뢰감을 주는 댓글을 베스트 댓글로 만드는 인공지능 프로그램을 개발한다.
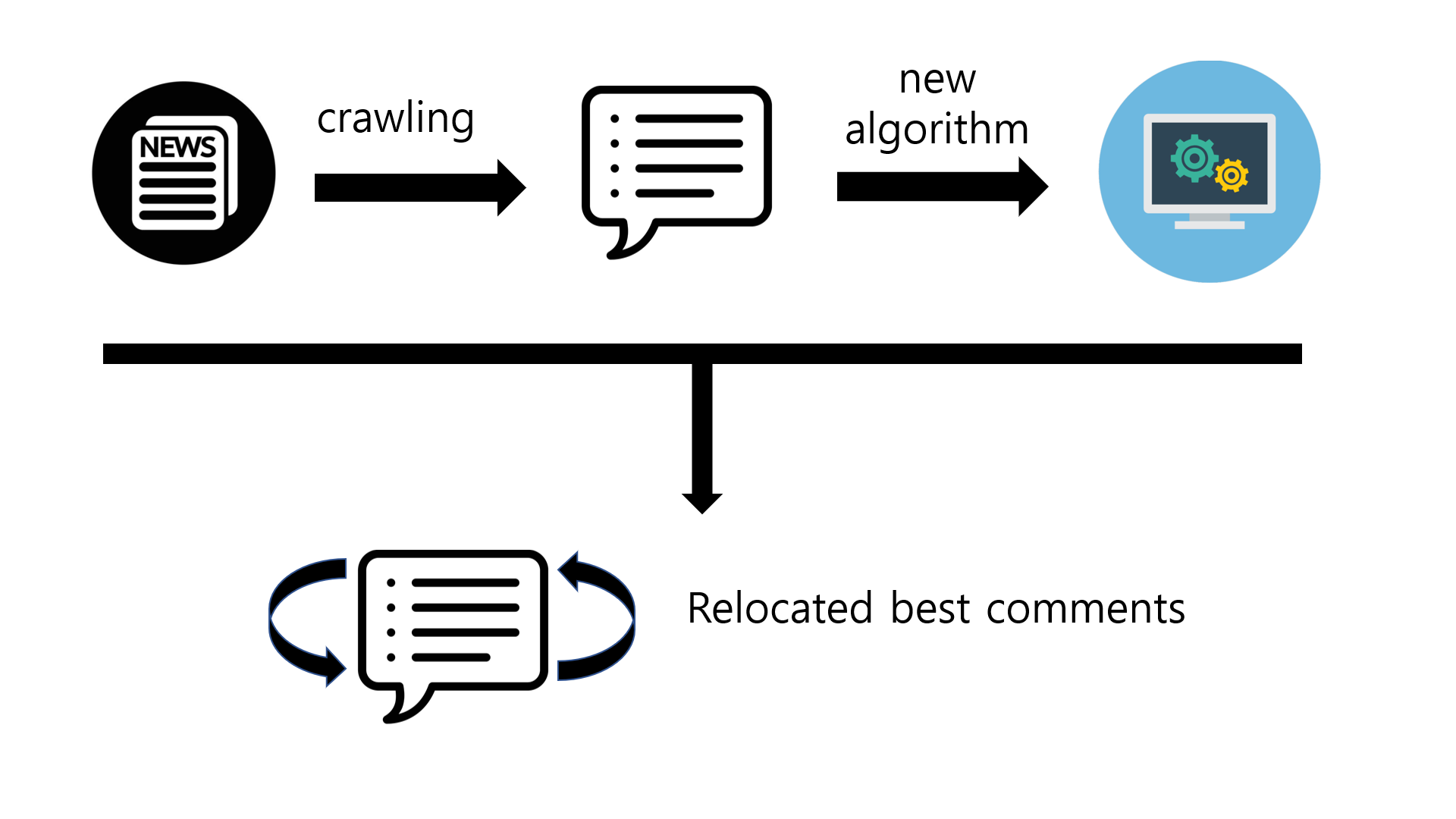
위 그림은 본 연구를 위한 프로그램을 제작하는 과정을 나타낸 것이다. 뉴스기사의 댓글을 크롤링하여 정리한 후, 편향성 측정 프로그램을 통해 베스트 댓글의 알고리즘을 바꾼다. 레이블에 따라 재배치된 베스트 댓글을 대중들에게 공개하여 이전과 비교하며 댓글에 대한 인식을 조사한다.
연구의 필요성과 타당성을 입증하기 위해, 베스트 댓글의 알고리즘에 대한 설문조사를 실시하였다. 이를 위해 「생명윤리법 관련 온라인 교육과정」을 수료하였다. (교육과정 : 인간대상연구 및 인체유래물연구)
테스트 데이터는 네이버 댓글에서 가져오도록 하였다.
이 시스템의 첫 시작을 위해 구현해야할 기능은 크게 두가지이다.
첫 번째는 뉴스 기사 속의 네이버 댓글을 크롤링 해서 가져오는 것이고, 두 번째는 TextBlob을 사용하여 머신러닝 기반의 파이썬 텍스트 분류기를 생성하는 것이다.
크롤링을 위해 BeautifulSoup를 import한다.
https://apis.naver.com/commentBox/cbox/web_neo_list_jsonp.json?ticket=news&templateId=default_society&pool=cbox5&_callback=jQuery1707138182064460843_1523512042464&lang=ko&country=&objectId=news”+oid+”%2C”+aid+”&categoryId=&pageSize=20&indexSize=10&groupId=&listType=OBJECT&pageType=more&page=”+str(page)+”&refresh=false&sort=FAVORITE
위 API는 네이버 댓글을 추천순으로 긁어올 수 있는 네이버의 댓글 API URL이다.
1
2
3
4
5
6
7
r=requests.get(comments_url, headers=header)
cont=BeautifulSoup(r.content,"html.parser")
total_comm=str(cont).split('comment":')[1].split(",")[0]
match=re.findall('"contents":([^\*]*),"userIdNo"', str(cont))
댓글을 파싱하는 메인 코드이다. comments_url에 댓글 api url을 담는다. 종종 유용하게 쓰일 듯 하니 기록해두자.
댓글을 크롤링하면 결과가 출력된다.
이제 이렇게 크롤링한 댓글을 텍스트화 하여 긍정부정 판별 프로그램에 넣는다. 판별방법은 미리 입력된 데이터를 기반으로 하는 머신러닝에 기반하였다.
분석을 위해 NaiveBayesClassifier와 TextBlob을 import 한다. 기존의 학습데이터를 train에 넣고, NaiveBayesClassifier(train)를 cl에 넣어주었다. 크롤링한 댓글들은, 기존의 train 학습자료를 바탕으로 긍정과 부정의 척도가 a : b 비율로 나타내어진다.
유사한 방법으로 train데이터에서 편향성을 학습시켜, 댓글의 편향성 정도를 판별할 수 있다.
개선 사항
이 프로그램의 정확성을 높이기 위해 생각한 방법을 적어본다면,
첫번째는 데이터셋을 늘리는 것이다. 현재 이 프로그램은 데이터셋에 존재하지 않는, 새롭게 인식하는 단어의 판별이 매우 불안정하다. 레이블 값에서 가져올 판별대상이 없으므로 엉뚱한 결과가 출력되는 것이다. 머신러닝에 기반한 본 시스템은 데이터셋이 많아질수록 학습하는 데이터값이 늘어나므로, 데이터셋을 많이 구축해야한다.
두번째는 자연어처리를 사용하여, 형태소 분석을 하는 것이다. 한글은 매우 다양한 맺음말을 가지고 있다. 이 프로그램은 문장 자체를 전부 받아들여 문장내의 단어로 편향성을 판별하므로, 맺음말이 다른 경우 다른 단어로 인식하여 각각 다른 결과를 출력한다. (ex. 힘듦, 힘들다, 힘들었음) 따라서 문장을 학습하는 것에서 더 깊이 들어가, 문장 내의 형태소를 분석하여 판별하면 맺음말에 따라 다르게 판별하는 경우가 사라지므로 정확성이 올라갈 것이다. (ex. ‘나쁘다’를 학습하는 것이 아니라 ‘나ㅃ-‘ + [종성 또는 어미]로 분석하여 학습한다)